Redis知识点汇总
概念
- C 语言写成的,开源的 key-value 数据库
- 和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set 使用score排序)和hash(哈希类型)
- 这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
- 与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步
对比memcached
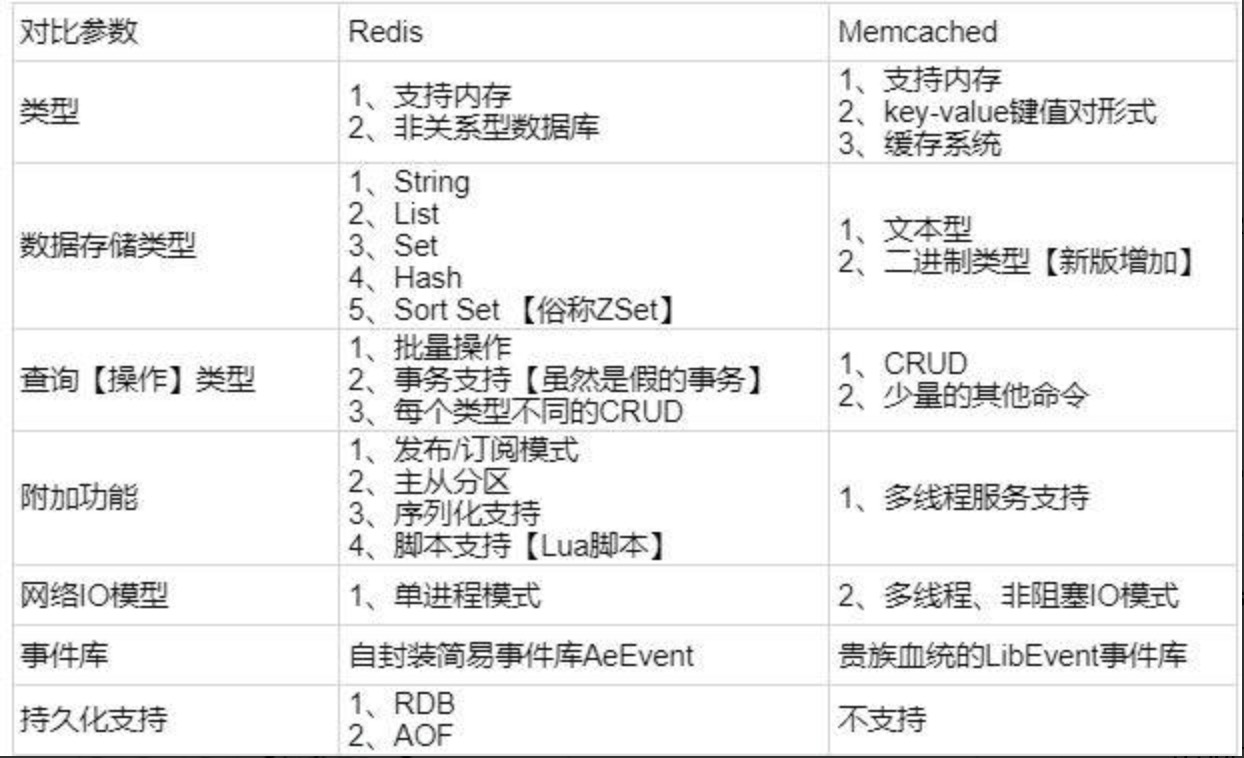
- Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
- Redis支持数据的备份,即master-slave模式的数据备份。
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中
- redis的速度比memcached快很多
Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的IO复用模型。
终极策略: 使用Redis的String类型做的事,都可以用Memcached替换,以此换取更好的性能提升; 除此以外,优先考虑Redis
优势
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2)支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务 :redis对事务是部分支持的,如果是在入队时报错,那么都不会执行;在非入队时报错,那么成功的就会成功执行。
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
操作
- 字符串操作: SET/GET
- 哈希类型操作:HMSET/ HGETALL/ HSET
- 列表(链表):LPUSH/ RPUSH/ LPOP/ RPOP/ LRANGE
- 集合:SADD/ SMEMBERS
- 有序集合(ZSET):ZADD/ ZRANGE
- HyperLogLog(集合基数统计):PFADD/ PFCOUNT/ PFMERGE
- 2.8+ 扫描操作:SCAN/ SSCAN/ HSCAN/ ZSCAN
- 发布订阅
- 发布订阅模式,两个客户端之间通过SUBSCRIBE/ PULISH交换消息
- 命令:PUBLISH/ SUBSCRIBE/ PUBSUB
- 事务
- 从开始到执行会进入以下步骤:开始事务—进入队列—执行事务
- 事务可以认为是一个批量执行的脚本,内部命令是原子的,但事务本身并非原子。中间的命令失败不会导致其之前命令回滚,也不会导致其之后命令放弃执行
- 命令:
- MULTI(标记事务开始)
- EXEC(开始执行事务)
- DISCARD(放弃执行事务块)
- 脚本:EVAL script numkeys key [key …] arg [arg …]
- 备份与恢复
- 备份:
SAVE命令存储数据到dump.rdb,CONFIG GET dir查看rdb文件存储位置,将文件备份 - 恢复:只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
- 备份:
- 性能测试:
redis-benchmark -n 10000 -q
keys 和 SCAN
- keys {pattern} 获取所有符合pattern 的key
- 没有offset和limit参数,会返回所有的key
- 复杂度O(n), 当n较大时导致redis服务卡顿
- 由于redis是单线程的,会阻塞redis后续的命令
- scan {cursor} [MATCH pattern] [COUNT count]
- 复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程;
- 提供 count 参数,可以控制每次返回结果的最大条数,count 只是对增量式迭代命令的一种提示(hint),返回的结果可多可少;
- 同 keys 一样,它也提供模式匹配功能;
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
- 返回的结果可能会有重复,需要客户端去重复,这点非常重要;
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零
一些规范
参考推送
Key 名称设计:
在尽量保持可读性的前提下,缩短key的长度
user:{uid}:friends:messages:{mid} 简化为 u:{uid}:fr:m:{mid}。
value 设计:
- 拒绝bigkey,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
- 如果你观察到 Redis 的内存大起大落,这极有可能是因为大 key 导致的,这时候你就需要定位出具体是哪个 key,
redis-cli --bigkeys -i 0.1 # 每隔100条scan就会休眠0.1s命令可以用来找到。 - 非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会不出现在慢查询中(latency可查)),查找方法和删除方法
- 选择适合的数据类型
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期),不过期的数据重点关注idletime。
避免一些在n比较大时的O(n)操作,禁用一些危险命令,可在conf文件中使用
rename-command flushdb flushddbb命令对危险命令进行重命名使用如原生的
mgetmset或非原生的pipline这种批量命令来提高效率,不建议过多使用事务功能
避免多个应用使用一个redis实例,不想干业务拆分,公共数据做服务化
根据自身业务类型,选好maxmemory-policy(最大内存淘汰策略),设置好过期时间。
默认策略是volatile-lru,即超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
其他策略如下:
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random:随机删除过期键,直到腾出足够空间为止。
- volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息”(error) OOM command not allowed when used memory”,此时Redis只响应读操作。
Jedis下删除bigkeys的一些代码示例
- Hash删除: hscan + hdel
1 | public void delBigHash(String host, int port, String password, String bigHashKey) { |
- List删除: ltrim
1 | public void delBigList(String host, int port, String password, String bigListKey) { |
- Set删除: sscan + srem
1 | public void delBigSet(String host, int port, String password, String bigSetKey) { |
- SortedSet删除: zscan + zrem
1 | public void delBigZset(String host, int port, String password, String bigZsetKey) { |